karel的深度神经网络
翻译:wbgxx333@163.com
时间:2014年4月翻译,2015年4月重新修改翻译
综述
这个文档主要来说kaldi中Karel Vesely部分的深度神经网络代码。
如果想了解kaldi的全部深度神经网络代码,请Deep Neural Networks in Kaldi, 和Dan的版本, 请看Dan's DNN implementation。
这个文档的目标就是更加详细的介绍DNN部分,和简单介绍神经网络训练工具。我们将从Top-level script开始, 解释the Training script internals到底做了什么, 展示一些Advanced features, 和对The C++ code做了一些简单的介绍,和解释如何来扩展这些。
Top-level script
让我们来看一下脚本egs/wsj/s5/local/nnet/run_dnn.sh。这个脚本是使用单CUDA GPU,和使用CUDA编译过的kaldi(可以在 src/kaldi.mk中使用'CUDA = true'来检查)。我们也假设'cuda_cmd'在egs/wsj/s5/cmd.sh里设置是正确的,或者是使用'queue.pl'的GPU集群节点,或者是使用'run.pl'的本地机器。最后假设我们由egs/wsj/s5/run.sh得到了一个SAT GMM系统exp/tri4b和对应的fMLLR变换。注意其他数据库的 run_dnn.sh一般都会在s5/local/nnet/run_dnn.sh.
脚本 egs/wsj/s5/local/nnet/run_dnn.sh分下面这些步骤:
0.存储在本地的40维fMLLR特征, 使用steps/nnet/make_fmllr_feats.sh,这简化了训练脚本,40维的特征是使用CMN的MFCC-LDA-MLLT-fMLLR。
1. RBM 预训练, steps/nnet/pretrain_dbn.sh,是根据Geoff Hinton's tutorial paper来实现的。训练方法是使用1步马尔科夫链蒙特卡罗采样的对比散度算法(CD-1)。 第一层的RBM是Gaussian-Bernoulli,和接下来的RBMs是Bernoulli-Bernoulli。这里的超参数基准是在100h Switchboard subset数据集上调参得到的。如果数据集很小的话,迭代次数N就需要变为100h/set_size。训练是无监督的,所以可以提供足够多的输入特征数据目录。
当训练Gaussian-Bernoulli的RBM时,将有很大的风险面临权重爆炸,尤其是在很大的学习率和成千上万的隐层神经元上。为了避免权重爆炸,在实现时我们需要在一个minbatch上比较训练数据的方差和重构数据的方差。如果重构的方差是训练数据的2倍以上,权重将缩小和学习率将暂时减小。
2. 帧交叉熵训练,steps/nnet/train.sh, 这个阶段是训练一个DNN来把帧分到对应的三音素状态(比如: PDFs)中。这是通过mini-batch随机梯度下降法来做的。(译者注:mini-batch指的就是分批处理,它的错误率表示的:每一次epoch中,所有的小batch的平均损失函数值;而full-batch是完整的数据集,它的错误率表示:一次epoch中,整个大batch的损失函数值。)默认的是使用Sigmoid隐层单元,Softmax输出单元和全连接层AffineTransform。学习率是0.008,minibatch的大小是256;这里我们未使用冲量和正则化(注: 最佳的学习率与不同的隐含层单元类型有关,sigmoid的值0.008,tanh是0.00001)。
输入变换和预训练DBN(比如:深度信念网络,RBMs块)是使用选项 '–input-transform'和'–dbn'传递给脚本的,这里仅仅输出层是随机初始化的。我们使用提早停止(early stopping)来防止过拟合。为了这个,我们需要在交叉验证集(比如: held-out set)上计算代价函数,因此两对特征对齐目录需要做有监督的训练。
对DNN训练有一个好的总结文章是http://research.google.com/pubs/archive/38131.pdf
3.,4.,5.,6. sMBR序列区分性训练,steps/nnet/train_mpe.sh, 这个阶段对所有的句子联合优化来训练神经网络,比帧层训练更接近一般的ASR目标。
- sMBR的目标是最大化从参考的对齐中得到的状态标签的期望正确率,然而这里使用一个词图框架是来表示这种竞争假设。
- 训练是使用每句迭代的随机梯度下降法,我们还使用一个低的固定的学习率1e-5 (sigmoids)和跑3-5轮。
- 当在第一轮迭代后重新生成词图,我们观察到快速收敛。我们支持MMI, BMMI, MPE 和sMBR训练。所有的技术在Switchboard 100h集上是相同的,仅仅在sMBR好一点点。
- 在sMBR优化中,我们在计算近似正确率的时候忽略了静音帧。具体更加详细的描述见http://www.danielpovey.com/files/2013_interspeech_dnn.pdf
其他一些有意思的top-level scripts:
除了DNN脚本,这里也有一些其他的脚本:
- DNN : egs/wsj/s5/local/nnet/run_dnn.sh , (main top-level script)
- CNN : egs/rm/s5/local/nnet/run_cnn.sh , (CNN = Convolutional Neural Network, see paper, we have 1D convolution on frequency axis)
- Autoencoder training : egs/timit/s5/local/nnet/run_autoencoder.sh
- Tandem system : egs/swbd/s5c/local/nnet/run_dnn_tandem_uc.sh , (uc = Universal context network, see paper)
- Multilingual/Multitask : egs/rm/s5/local/nnet/run_multisoftmax.sh, (Network with
output trained on RM and WSJ, same C++ design as was used in SLT2012 paper)
Training script internals
主要的神经网络训练脚本steps/nnet/train.sh的调用如下:
steps/nnet/train.sh <data-train> <data-dev> <lang-dir> <ali-train> <ali-dev> <exp-dir>
神经网络的输入特征是从数据目录<data-train><data-dev>中获得的,训练的目标是从目录<ali-train> <ali-dev>得到的。目录<lang-dir>仅仅在使用LDA特征变换时才被使用,和从对齐中生成音素帧的统计量,这个对于训练不是很重要。输出(比如:训练得到的网络和log文件)都存到<exp-dir>。
在内部,脚本需要准备特征和目标基准,从而产生一个神经网络的原型和初始化,建立特征变换和使用调度脚本 steps/nnet/train_scheduler.sh,用来跑训练迭代次数和控制学习率。
当看steps/nnet/train.sh脚本内部时,我们将看到:
CUDA是需要的,如果没有检测到GPU或者CUDA没有被编译,脚本将退出。(你可以坚持使用'–skip-cuda-check true'来使用CPU运行,但是速度将慢10-20倍)
对齐基准需要提前准备,训练工具需要的目标是以后验概率格式,因此ali-to-post.cc被使用:
labels_tr="ark:ali-to-pdf $alidir/final.mdl \"ark:gunzip -c $alidir/ali.*.gz |\" ark:- | ali-to-post ark:- ark:- |" labels_cv="ark:ali-to-pdf $alidir/final.mdl \"ark:gunzip -c $alidir_cv/ali.*.gz |\" ark:- | ali-to-post ark:- ark:- |"重组的特征拷贝到/tmp/???/...,如果使用'–copy-feats false',这个将失效。或者目录改为
–copy-feats-tmproot <dir>。- 特征使用调用列表被重新保存到本地,这些显著地降低了在训练过程中磁盘的重要性,它防止了大量磁盘访问的操作。
特征基准被准备:
# begins with copy-feats: feats_tr="ark:copy-feats scp:$dir/train.scp ark:- |" feats_cv="ark:copy-feats scp:$dir/cv.scp ark:- |" # optionally apply-cmvn is appended: feats_tr="$feats_tr apply-cmvn --print-args=false --norm-vars=$norm_vars --utt2spk=ark:$data/utt2spk scp:$data/cmvn.scp ark:- ark:- |" feats_cv="$feats_cv apply-cmvn --print-args=false --norm-vars=$norm_vars --utt2spk=ark:$data_cv/utt2spk scp:$data_cv/cmvn.scp ark:- ark:- |" # optionally add-deltas is appended: feats_tr="$feats_tr add-deltas --delta-order=$delta_order ark:- ark:- |" feats_cv="$feats_cv add-deltas --delta-order=$delta_order ark:- ark:- |"特征变换被准备:
- 特征变换在DNN前端处理中是一个固定的函数,是通过GPU来计算的。一般来说,它会导致维度爆炸。这就要使得在磁盘上有低维的特征和DNN前端处理的高维特征, 即节约了磁盘空间,由节约了读取吞吐量。
- 大多数的nnet-binaries有选项'–feature-transform'
- 它的产生依赖于选项'–feat-type',它的值是(plain|traps|transf|lda)。
网络的原型是由utils/nnet/make_nnet_proto.py产生的:
- 每个成分在单独一行上,这里的维度和初始化的超参数是指定的;
- 对于AffineTransform,偏移量的初始化是的均匀分布给定
<BiasMean>和<BiasRange>的均匀分布,而权重的初始化是通过通过对<ParamStddev>拉伸的正态分布; - 注意:如果你喜欢使用外部准备的神经网络原型来实验,可以使用选项'–mlp-proto
';
$ cat exp/dnn5b_pretrain-dbn_dnn/nnet.proto <NnetProto> <AffineTransform> <InputDim> 2048 <OutputDim> 3370 <BiasMean> 0.000000 <BiasRange> 0.000000 <ParamStddev> 0.067246 <Softmax> <InputDim> 3370 <OutputDim> 3370 </NnetProto>神经网络是通过nnet-initialize.cc来初始化。下一步中, DBN是通过使用nnet-concat.cc得到的。
最终训练是通过运行调度脚本steps/nnet/train_scheduler.sh来完成的。
注:无论神经网络还是特征变换都可以使用nnet-info.cc来观看,或者用nnet-copy.cc来显示。
当具体看steps/nnet/train_scheduler.sh,我们可以看到:
一开始需要在交叉验证集上运行,和主函数需要根据$iter来运行迭代次数和控制学习率。典型的情况就是,train_scheduler.sh被train.sh调用
- 默认的学习率的变化是根据目标函数相对性的提高来决定的:
- 如果提高大于'start_halving_impr=0.01',初始化学习率保持常数
- 然后学习率在每次迭代中乘以'halving_factor=0.5'来缩小
- 最后,如果提高小于'end_halving_impr=0.001',训练被终止。
神经网络被保存在$dir/nnet,log文件被保存在$dir/log:
神经网络的名字包含迭代的次数,学习率和在训练和交叉验证集上的目标函数值
- 我们可以看到从第五次迭代开始,学习率减半,这是一个普通的情况。
$ ls exp/dnn5b_pretrain-dbn_dnn/nnet nnet_6.dbn_dnn_iter01_learnrate0.008_tr1.1919_cv1.5895 nnet_6.dbn_dnn_iter02_learnrate0.008_tr0.9566_cv1.5289 nnet_6.dbn_dnn_iter03_learnrate0.008_tr0.8819_cv1.4983 nnet_6.dbn_dnn_iter04_learnrate0.008_tr0.8347_cv1.5097_rejected nnet_6.dbn_dnn_iter05_learnrate0.004_tr0.8255_cv1.3760 nnet_6.dbn_dnn_iter06_learnrate0.002_tr0.7920_cv1.2981 nnet_6.dbn_dnn_iter07_learnrate0.001_tr0.7803_cv1.2412 ... nnet_6.dbn_dnn_iter19_learnrate2.44141e-07_tr0.7770_cv1.1448 nnet_6.dbn_dnn_iter20_learnrate1.2207e-07_tr0.7769_cv1.1446 nnet_6.dbn_dnn_iter20_learnrate1.2207e-07_tr0.7769_cv1.1446_final_
- 我们可以看到从第五次迭代开始,学习率减半,这是一个普通的情况。
训练集和交叉验证集分别存储了对应的log文件。 每一个log文件命令行:
$ cat exp/dnn5b_pretrain-dbn_dnn/log/iter01.tr.log nnet-train-frmshuff --learn-rate=0.008 --momentum=0 --l1-penalty=0 --l2-penalty=0 --minibatch-size=256 --randomizer-size=32768 --randomize=true --verbose=1 --binary=true --feature-transform=exp/dnn5b_pretrain-dbn_dnn/final.feature_transform --randomizer-seed=777 'ark:copy-feats scp:exp/dnn5b_pretrain-dbn_dnn/train.scp ark:- |' 'ark:ali-to-pdf exp/tri4b_ali_si284/final.mdl "ark:gunzip -c exp/tri4b_ali_si284/ali.*.gz |" ark:- | ali-to-post ark:- ark:- |' exp/dnn5b_pretrain-dbn_dnn/nnet_6.dbn_dnn.init exp/dnn5b_pretrain-dbn_dnn/nnet/nnet_6.dbn_dnn_iter01
gpu被使用的信息:
LOG (nnet-train-frmshuff:IsComputeExclusive():cu-device.cc:214) CUDA setup operating under Compute Exclusive Process Mode.
LOG (nnet-train-frmshuff:FinalizeActiveGpu():cu-device.cc:174) The active GPU is [1]: GeForce GTX 780 Ti free:2974M, used:97M, total:3071M, free/total:0.968278 version 3.5
从神经网络训练得到的内部统计量是通过函数 Nnet::InfoPropagate,Nnet::InfoBackPropagate 和 Nnet::InfoGradient来准备的。它们将在迭代的一开始打印和迭代的最后一次进行第二次打印。注意当我们实现新的特征来做网络训练时,每一个成分的统计量就尤其便利地计算,所以我们可以比较参考的值和期望的值:
VLOG[1] (nnet-train-frmshuff:main():nnet-train-frmshuff.cc:236) ### After 0 frames,
VLOG[1] (nnet-train-frmshuff:main():nnet-train-frmshuff.cc:237) ### Forward propagation buffer content :
[1] output of <Input> ( min -6.1832, max 7.46296, mean 0.00260791, variance 0.964268, skewness -0.0622335, kurtosis 2.18525 )
[2] output of <AffineTransform> ( min -18.087, max 11.6435, mean -3.37778, variance 3.2801, skewness -3.40761, kurtosis 11.813 )
[3] output of <Sigmoid> ( min 1.39614e-08, max 0.999991, mean 0.085897, variance 0.0249875, skewness 4.65894, kurtosis 20.5913 )
[4] output of <AffineTransform> ( min -17.3738, max 14.4763, mean -2.69318, variance 2.08086, skewness -3.53642, kurtosis 13.9192 )
[5] output of <Sigmoid> ( min 2.84888e-08, max 0.999999, mean 0.108987, variance 0.0215204, skewness 4.78276, kurtosis 21.6807 )
[6] output of <AffineTransform> ( min -16.3061, max 10.9503, mean -3.65226, variance 2.49196, skewness -3.26134, kurtosis 12.1138 )
[7] output of <Sigmoid> ( min 8.28647e-08, max 0.999982, mean 0.0657602, variance 0.0212138, skewness 5.18622, kurtosis 26.2368 )
[8] output of <AffineTransform> ( min -19.9429, max 12.5567, mean -3.64982, variance 2.49913, skewness -3.2291, kurtosis 12.3174 )
[9] output of <Sigmoid> ( min 2.1823e-09, max 0.999996, mean 0.0671024, variance 0.0216422, skewness 5.07312, kurtosis 24.9565 )
[10] output of <AffineTransform> ( min -16.79, max 11.2748, mean -4.03986, variance 2.15785, skewness -3.13305, kurtosis 13.9256 )
[11] output of <Sigmoid> ( min 5.10745e-08, max 0.999987, mean 0.0492051, variance 0.0194567, skewness 5.73048, kurtosis 32.0733 )
[12] output of <AffineTransform> ( min -24.0731, max 13.8856, mean -4.00245, variance 2.16964, skewness -3.14425, kurtosis 16.7714 )
[13] output of <Sigmoid> ( min 3.50889e-11, max 0.999999, mean 0.0501351, variance 0.0200421, skewness 5.67209, kurtosis 31.1902 )
[14] output of <AffineTransform> ( min -2.53919, max 2.62531, mean -0.00363421, variance 0.209117, skewness -0.0302545, kurtosis 0.63143 )
[15] output of <Softmax> ( min 2.01032e-05, max 0.00347782, mean 0.000296736, variance 2.08593e-08, skewness 6.14324, kurtosis 35.6034 )
VLOG[1] (nnet-train-frmshuff:main():nnet-train-frmshuff.cc:239) ### Backward propagation buffer content :
[1] diff-output of <AffineTransform> ( min -0.0256142, max 0.0447016, mean 1.60589e-05, variance 7.34959e-07, skewness 1.50607, kurtosis 97.2922 )
[2] diff-output of <Sigmoid> ( min -0.10395, max 0.20643, mean -2.03144e-05, variance 5.40825e-05, skewness 0.226897, kurtosis 10.865 )
[3] diff-output of <AffineTransform> ( min -0.0246385, max 0.033782, mean 1.49055e-05, variance 7.2849e-07, skewness 0.71967, kurtosis 47.0307 )
[4] diff-output of <Sigmoid> ( min -0.137561, max 0.177565, mean -4.91158e-05, variance 4.85621e-05, skewness 0.020871, kurtosis 7.7897 )
[5] diff-output of <AffineTransform> ( min -0.0311345, max 0.0366407, mean 1.38255e-05, variance 7.76937e-07, skewness 0.886642, kurtosis 70.409 )
[6] diff-output of <Sigmoid> ( min -0.154734, max 0.166145, mean -3.83602e-05, variance 5.84839e-05, skewness 0.127536, kurtosis 8.54924 )
[7] diff-output of <AffineTransform> ( min -0.0236995, max 0.0353677, mean 1.29041e-05, variance 9.17979e-07, skewness 0.710979, kurtosis 48.1876 )
[8] diff-output of <Sigmoid> ( min -0.103117, max 0.146624, mean -3.74798e-05, variance 6.17777e-05, skewness 0.0458594, kurtosis 8.37983 )
[9] diff-output of <AffineTransform> ( min -0.0249271, max 0.0315759, mean 1.0794e-05, variance 1.2015e-06, skewness 0.703888, kurtosis 53.6606 )
[10] diff-output of <Sigmoid> ( min -0.147389, max 0.131032, mean -0.00014309, variance 0.000149306, skewness 0.0190403, kurtosis 5.48604 )
[11] diff-output of <AffineTransform> ( min -0.057817, max 0.0662253, mean 2.12237e-05, variance 1.21929e-05, skewness 0.332498, kurtosis 35.9619 )
[12] diff-output of <Sigmoid> ( min -0.311655, max 0.331862, mean 0.00031612, variance 0.00449583, skewness 0.00369107, kurtosis -0.0220473 )
[13] diff-output of <AffineTransform> ( min -0.999905, max 0.00347782, mean -1.33212e-12, variance 0.00029666, skewness -58.0197, kurtosis 3364.53 )
VLOG[1] (nnet-train-frmshuff:main():nnet-train-frmshuff.cc:240) ### Gradient stats :
Component 1 : <AffineTransform>,
linearity_grad ( min -0.204042, max 0.190719, mean 0.000166458, variance 0.000231224, skewness 0.00769091, kurtosis 5.07687 )
bias_grad ( min -0.101453, max 0.0885828, mean 0.00411107, variance 0.000271452, skewness 0.728702, kurtosis 3.7276 )
Component 2 : <Sigmoid>,
Component 3 : <AffineTransform>,
linearity_grad ( min -0.108358, max 0.0843307, mean 0.000361943, variance 8.64557e-06, skewness 1.0407, kurtosis 21.355 )
bias_grad ( min -0.0658942, max 0.0973828, mean 0.0038158, variance 0.000288088, skewness 0.68505, kurtosis 1.74937 )
Component 4 : <Sigmoid>,
Component 5 : <AffineTransform>,
linearity_grad ( min -0.186918, max 0.141044, mean 0.000419367, variance 9.76016e-06, skewness 0.718714, kurtosis 40.6093 )
bias_grad ( min -0.167046, max 0.136064, mean 0.00353932, variance 0.000322016, skewness 0.464214, kurtosis 8.90469 )
Component 6 : <Sigmoid>,
Component 7 : <AffineTransform>,
linearity_grad ( min -0.134063, max 0.149993, mean 0.000249893, variance 9.18434e-06, skewness 1.61637, kurtosis 60.0989 )
bias_grad ( min -0.165298, max 0.131958, mean 0.00330344, variance 0.000438555, skewness 0.739655, kurtosis 6.9461 )
Component 8 : <Sigmoid>,
Component 9 : <AffineTransform>,
linearity_grad ( min -0.264095, max 0.27436, mean 0.000214027, variance 1.25338e-05, skewness 0.961544, kurtosis 184.881 )
bias_grad ( min -0.28208, max 0.273459, mean 0.00276327, variance 0.00060129, skewness 0.149445, kurtosis 21.2175 )
Component 10 : <Sigmoid>,
Component 11 : <AffineTransform>,
linearity_grad ( min -0.877651, max 0.811671, mean 0.000313385, variance 0.000122102, skewness -1.06983, kurtosis 395.3 )
bias_grad ( min -1.01687, max 0.640236, mean 0.00543326, variance 0.00977744, skewness -0.473956, kurtosis 14.3907 )
Component 12 : <Sigmoid>,
Component 13 : <AffineTransform>,
linearity_grad ( min -22.7678, max 0.0922921, mean -5.66685e-11, variance 0.00451415, skewness -151.169, kurtosis 41592.4 )
bias_grad ( min -22.8996, max 0.170164, mean -8.6555e-10, variance 0.421778, skewness -27.1075, kurtosis 884.01 )
Component 14 : <Softmax>,
有一个全部数据集的目标函数值的总结log文件,它的progress vector是由第一步产生的,和帧正确率为:
LOG (nnet-train-frmshuff:main():nnet-train-frmshuff.cc:273) Done 34432 files, 21 with no tgt_mats, 0 with other errors. [TRAINING, RANDOMIZED, 50.8057 min, fps8961.77]
LOG (nnet-train-frmshuff:main():nnet-train-frmshuff.cc:282) AvgLoss: 1.19191 (Xent), [AvgXent: 1.19191, AvgTargetEnt: 0]
progress: [3.09478 1.92798 1.702 1.58763 1.49913 1.45936 1.40532 1.39672 1.355 1.34153 1.32753 1.30449 1.2725 1.2789 1.26154 1.25145 1.21521 1.24302 1.21865 1.2491 1.21729 1.19987 1.18887 1.16436 1.14782 1.16153 1.1881 1.1606 1.16369 1.16015 1.14077 1.11835 1.15213 1.11746 1.10557 1.1493 1.09608 1.10037 1.0974 1.09289 1.11857 1.09143 1.0766 1.08736 1.10586 1.08362 1.0885 1.07366 1.08279 1.03923 1.06073 1.10483 1.0773 1.0621 1.06251 1.07252 1.06945 1.06684 1.08892 1.07159 1.06216 1.05492 1.06508 1.08979 1.05842 1.04331 1.05885 1.05186 1.04255 1.06586 1.02833 1.06131 1.01124 1.03413 0.997029 ]
FRAME_ACCURACY >> 65.6546% <<
log文件的结尾是CUDA的信息,CuMatrix::AddMatMat是矩阵乘法和大多数的花费时间如下:
[cudevice profile]
Destroy 23.0389s
AddVec 24.0874s
CuMatrixBase::CopyFromMat(from other CuMatrixBase) 29.5765s
AddVecToRows 29.7164s
CuVector::SetZero 37.7405s
DiffSigmoid 37.7669s
CuMatrix::Resize 41.8662s
FindRowMaxId 42.1923s
Sigmoid 48.6683s
CuVector::Resize 56.4445s
AddRowSumMat 75.0928s
CuMatrix::SetZero 86.5347s
CuMatrixBase::CopyFromMat(from CPU) 166.27s
AddMat 174.307s
AddMatMat 1922.11s
直接运行steps/nnet/train_scheduler.sh:
- 脚本train_scheduler.sh可以被train.sh调用,它允许覆盖默认的NN-input和NN-target streams,可以很便利的设置。
- 然而这个脚本假设所有的设置是正确的,仅仅对高级用户来说是合适的。
- 在直接调用前,我们非常建议去看脚本train_scheduler.sh是如何调用的。
Training tools
与nnet1相关的代码在目录src/nnetbin下,重要的工具如下:
- nnet-train-frmshuff.cc :最普遍使用的神经网络训练工具,执行一次迭代训练。
nnet-forward.cc : 通过神经网络计算前向数据,默认使用CPU
看选项:
- –apply-log :产生神经网络的对数输出(比如:得到对数后验概率)
- –no-softmax :从模型中去掉soft-max层(decoding with pre-softmax values leads to the same lattices as with log-posteriors)
- –class-frame-counts : counts to calculate log-priors, which get subtracted from the acoustic scores (在解码中的一个典型的技巧).
rbm-train-cd1-frmshuff.cc :使用CD1来训练RBM,当内部调整学习率/冲量时需要训练数据好几次。
- nnet-train-mmi-sequential.cc : MMI / bMMI DNN training
- nnet-train-mpe-sequential.cc : MPE / sMBR DNN training
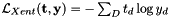
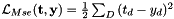 这里的
这里的 表示目标向量
表示目标向量 的元素,
的元素, 是DNN输出向量
是DNN输出向量 的元素,和D是DNN输出的维度。
的元素,和D是DNN输出的维度。Other tools
- nnet-info.cc 打印关于神经网络的信息
- nnet-copy.cc 使用选项–binary=false把神经网络转换为ASCII格式,可以用来移除某些成分
Showing the network topology with nnet-info
接下来从nnet-info.cc里的打印信息显示"feature_transform"与steps/nnet/train.sh里的'–feat-type plain'相对应,它包含三个成分:
<Splice>:拼帧操作,对中间帧使用左右的上下文的帧 [ -5 -4 -3 -2 -1 0 1 2 3 4 5 ]<Addshift>:把特征变为零均值<Rescale>:把特征变成单位方差- 注意:我们从磁盘中读取低维特征,通过选项"feature_transform"扩展到高维特征,这样会节省磁盘空间和可读的吞吐量。
$ nnet-info exp/dnn5b_pretrain-dbn_dnn/final.feature_transform num-components 3 input-dim 40 output-dim 440 number-of-parameters 0.00088 millions component 1 : <Splice>, input-dim 40, output-dim 440, frame_offsets [ -5 -4 -3 -2 -1 0 1 2 3 4 5 ] component 2 : <AddShift>, input-dim 440, output-dim 440, shift_data ( min -0.265986, max 0.387861, mean -0.00988686, variance 0.00884029, skewness 1.36947, kurtosis 7.2531 ) component 3 : <Rescale>, input-dim 440, output-dim 440, scale_data ( min 0.340899, max 1.04779, mean 0.838518, variance 0.0265105, skewness -1.07004, kurtosis 0.697634 ) LOG (nnet-info:main():nnet-info.cc:57) Printed info about exp/dnn5b_pretrain-dbn_dnn/final.feature_transform
接下来会打印6层的神经网络信息:
每一层是由2个成分构成,一般
<AffineTransform>和一个非线性<Sigmoid>或者<Softmax>对于每一个
<AffineTransform>,对于权重和偏移量来说,一些统计量将分开显示(min, max, mean, variance, ...)$ nnet-info exp/dnn5b_pretrain-dbn_dnn/final.nnet num-components 14 input-dim 440 output-dim 3370 number-of-parameters 28.7901 millions component 1 : <AffineTransform>, input-dim 440, output-dim 2048, linearity ( min -8.31865, max 12.6115, mean 6.19398e-05, variance 0.0480065, skewness 0.234115, kurtosis 56.5045 ) bias ( min -11.9908, max 3.94632, mean -5.23527, variance 1.52956, skewness 1.21429, kurtosis 7.1279 ) component 2 : <Sigmoid>, input-dim 2048, output-dim 2048, component 3 : <AffineTransform>, input-dim 2048, output-dim 2048, linearity ( min -2.85905, max 2.62576, mean -0.00995374, variance 0.0196688, skewness 0.145988, kurtosis 5.13826 ) bias ( min -18.4214, max 2.76041, mean -2.63403, variance 1.08654, skewness -1.94598, kurtosis 29.1847 ) component 4 : <Sigmoid>, input-dim 2048, output-dim 2048, component 5 : <AffineTransform>, input-dim 2048, output-dim 2048, linearity ( min -2.93331, max 3.39389, mean -0.00912637, variance 0.0164175, skewness 0.115911, kurtosis 5.72574 ) bias ( min -5.02961, max 2.63683, mean -3.36246, variance 0.861059, skewness 0.933722, kurtosis 2.02732 ) component 6 : <Sigmoid>, input-dim 2048, output-dim 2048, component 7 : <AffineTransform>, input-dim 2048, output-dim 2048, linearity ( min -2.18591, max 2.53624, mean -0.00286483, variance 0.0120785, skewness 0.514589, kurtosis 15.7519 ) bias ( min -10.0615, max 3.87953, mean -3.52258, variance 1.25346, skewness 0.878727, kurtosis 2.35523 ) component 8 : <Sigmoid>, input-dim 2048, output-dim 2048, component 9 : <AffineTransform>, input-dim 2048, output-dim 2048, linearity ( min -2.3888, max 2.7677, mean -0.00210424, variance 0.0101205, skewness 0.688473, kurtosis 23.6768 ) bias ( min -5.40521, max 1.78146, mean -3.83588, variance 0.869442, skewness 1.60263, kurtosis 3.52121 ) component 10 : <Sigmoid>, input-dim 2048, output-dim 2048, component 11 : <AffineTransform>, input-dim 2048, output-dim 2048, linearity ( min -2.9244, max 3.0957, mean -0.00475199, variance 0.0112682, skewness 0.372597, kurtosis 25.8144 ) bias ( min -6.00325, max 1.89201, mean -3.96037, variance 0.847698, skewness 1.79783, kurtosis 3.90105 ) component 12 : <Sigmoid>, input-dim 2048, output-dim 2048, component 13 : <AffineTransform>, input-dim 2048, output-dim 3370, linearity ( min -2.0501, max 5.96146, mean 0.000392621, variance 0.0260072, skewness 0.678868, kurtosis 5.67934 ) bias ( min -0.563231, max 6.73992, mean 0.000585582, variance 0.095558, skewness 9.46447, kurtosis 177.833 ) component 14 : <Softmax>, input-dim 3370, output-dim 3370, LOG (nnet-info:main():nnet-info.cc:57) Printed info about exp/dnn5b_pretrain-dbn_dnn/final.nnet
Advanced features
Frame-weighted training
调用带选项的teps/nnet/train.sh:
--frame-weights <weights-rspecifier>
这里的<weights-rspecifier>
一般是表示每一帧权重的浮点型向量的ark文件。
- the weights are used to scale gradients computed on single frames, which is useful in confidence-weighted semi-supervised training,
- or weights can be used to mask-out frames we don't want to train with by generating vectors composed of weights 0, 1
Training with external targets
调用带选项的steps/nnet/train.sh:
--labels <posterior-rspecifier> --num-tgt <dim-output>
这里的ali-dirs和lang-dir变成虚设的目录。"
当每一帧使用一个单独的标签来训练时(比如:the 1-hot encoding),你可以准备一个跟输入特征一样长度的整数向量的ark文件。 这个整数向量的元素对目标类的索引进行编码,如果神经网络的输出是这个索引,那么对应的目标值为1。这个整数向量可以使用ali-to-post.cc来转换为Posterior,和这个整数向量格式是非常简单的:
utt1 0 0 0 0 1 1 1 1 1 2 2 2 2 2 2 ... 9 9 9
utt2 0 0 0 0 0 3 3 3 3 3 3 2 2 2 2 ... 9 9 9
在多种非零目标的情况下,你可以使用ascii格式准备Posterior
- 每一个非零的目标值是由一对
- 每一帧(比如:datapoint)是由括号[ ... ]里的值表示的,我们可以看到 数据对
utt1 [ 0 0.9991834 64 0.0008166544 ] [ 1 1 ] [ 0 1 ] [ 111 1 ] [ 0 1 ] [ 63 1 ] [ 0 1 ] [ 135 1 ] [ 0 1 ] [ 162 1 ] [ 0 1 ] [ 1 0.9937257 12 0.006274292 ] [ 0 1 ]
在自编码的例子里egs/timit/s5/local/nnet/run_autoencoder.sh,外部的目标被使用。
Mean-Square-Error training
调用带选项的steps/nnet/train.sh:
--train-tool "nnet-train-frmshuff --objective-function=mse"
--proto-opts "--no-softmax --activation-type=<Tanh> --hid-bias-mean=0.0 --hid-bias-range=1.0"
最小均方误差训练是用在自编码的例子里,在脚本egs/timit/s5/local/nnet/run_autoencoder.sh
Training with tanh
调用带选项的steps/nnet/train.sh:
--proto-opts "--activation-type=<Tanh> --hid-bias-mean=0.0 --hid-bias-range=1.0"
tanh的最佳学习率一般小于sigmoid,通常最佳为0.00001。
Conversion of a DNN model between nnet1 -> nnet2
在Kaldi中,有二个DNN的例子,一个是Karel's (本页)和Dan's Dan's DNN implementation。这两个使用不兼容的DNN格式,这里是把Karel's DNN 转换为Dan的格式。
- 模型转换的样例脚本为:egs/rm/s5/local/run_dnn_convert_nnet2.sh,
- 模型转换的脚本为: steps/nnet2/convert_nnet1_to_nnet2.sh, 它是通过调用模型转换代码来实现的:nnet1-to-raw-nnet.cc
- 支持成分的列表可以看ConvertComponent。
The C++ code
nnet1的代码位于src/nnet,工具在src/nnetbin。它是根据 src/cudamatrix。
Neural network representation
神经网络是由称为成分的块构成的,其中一些简单的例子就是AffineTransform或者一个非线性Sigmoid, Softmax。一个单独的DNN层一般是由2个成分构成: AffineTransform和一个非线性。
表示神经网络的类:Nnet is holding a vector of Component pointers Nnet::components_. Nnet最重要的一些方法如下:
- Nnet::Propagate : 从输入传播到输出,这里需要保证为梯度计算准备的 per-component buffers
- Nnet::Backpropagate : 通过损失函数来后向传播,更新权重
- Nnet::Feedforward :传播,当使用两个翻动buffer来节省内存
- Nnet::SetTrainOptions : 设置训练的超参数(比如:学习率,冲量,L1, L2-cost)
为了调试,成分和buffers块是通过Nnet::GetComponent, Nnet::PropagateBuffer, Nnet::BackpropagateBuffer可以看到的。
Extending the network by a new component
当创建一个新成分,你需要使用下面2个接口中的一个:
Component : a building block, 不包含任何训练的参数 (可以看例子里的实现nnet-activation.h)
UpdatableComponent : Component的孩子, 一个带训练参数的 building block(可以看例子里的声线nnet-affine-transform.h)
最重要的一些虚函数的实现方法是(不是一个完整的列表):
- Component::PropagateFnc : 前向传播函数
- Component::BackpropagateFnc : 后向传播函数(使用一步的链式法则,由后向传播函数的导数乘以损失函数的导数)
- UpdatableComponent::Update :梯度计算和权重更新
使用一个新的成分来扩展神经网络的框架,你需要:
- 定义一个新的成分入口Component::ComponentType
- 在表Component::kMarkerMap定义新的一行
- 添加一个"new Component"去调用像工厂一样的函数 Component::Read
- 实现接口Component或者 UpdatableComponent的所有虚函数方法